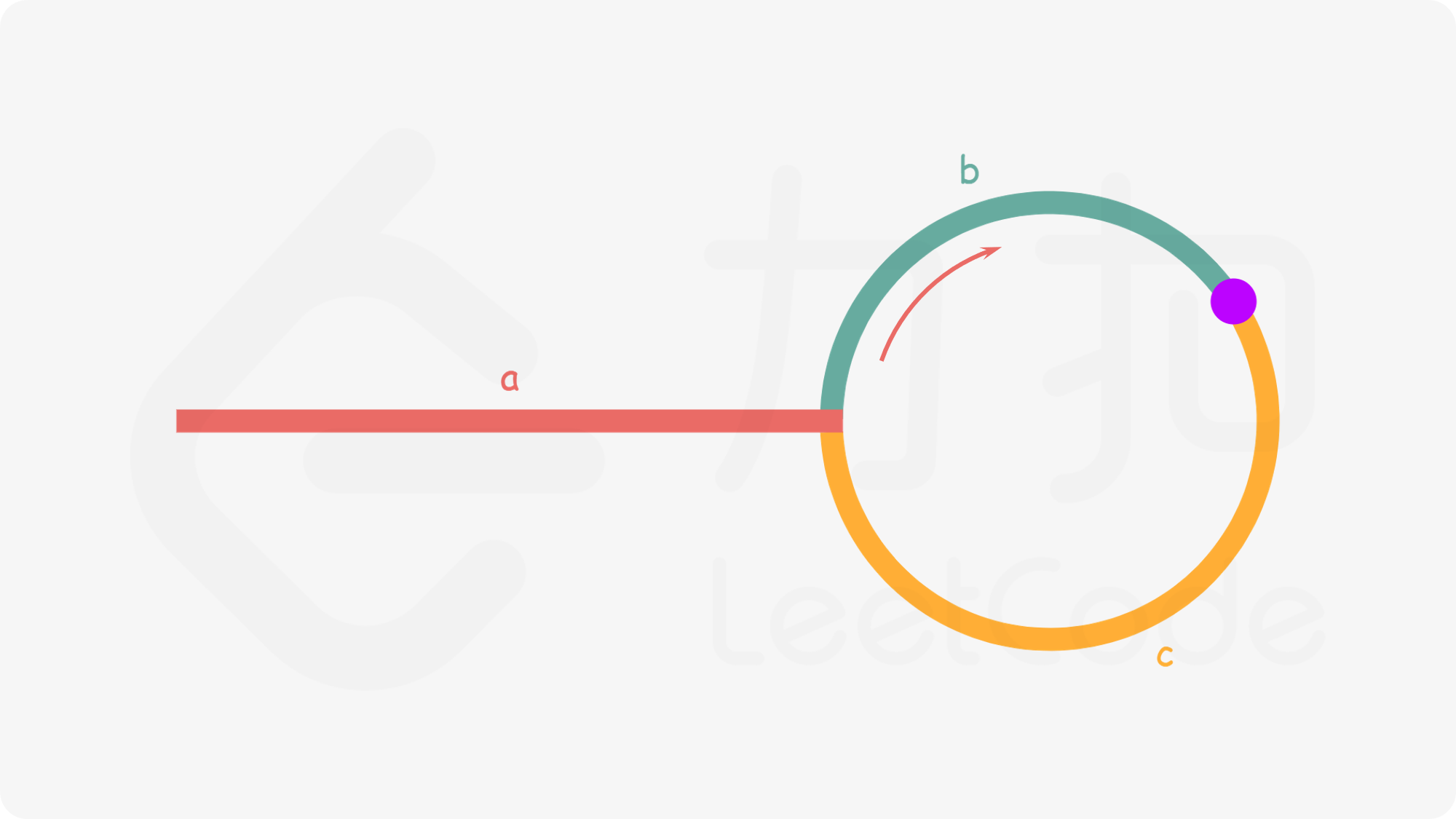# 一、理论基础也没什么特别的。离散存储、不支持随机访问。
链表节点的定义:
1 2 3 4 5 6 7 template <class T >struct _listNode { void * m_prev; void * m_next; T m_data; _listNode(T x) : m_data (x), m_next (nullptr ), m_prev (nullptr ) {} };
# 二、题目实践# 1、203. 移除链表元素 添加一个头节点,然后一次遍历即可。除了要释放我们移除的节点外,最后还要记得释放 dummy 节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public : ListNode* removeElements (ListNode* head, int val) { ListNode* pDummy = new ListNode (-1 , head); ListNode* pNow = pDummy; while (pNow->next != NULL ) { if (pNow->next->val == val) { ListNode* pDel = pNow->next; pNow->next = pDel->next; delete pDel; } else { pNow = pNow->next; } } head = pDummy->next; delete pDummy; return head; } };
# 2、707. 设计链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 struct MyNode { int val = 0 ; MyNode* next = nullptr ; MyNode () : val (0 ), next (nullptr ) {} MyNode (int x) : val (x), next (nullptr ) {} MyNode (int x, MyNode* p) : val (x), next (p) {} }; class MyLinkedList {public : MyLinkedList () : m_length (0 ) { m_head = new MyNode (-1 , nullptr ); } int get (int index) if (index >= m_length) { return -1 ; }; MyNode* pNow = m_head->next; while (index--) { pNow = pNow->next; } return pNow->val; } void addAtHead (int val) MyNode* pAdd = new MyNode (val, m_head->next); m_head->next = pAdd; m_length++; } void addAtTail (int val) MyNode* pAdd = new MyNode (val, nullptr ); MyNode* pNow = m_head; while (pNow->next) { pNow = pNow->next; } pNow->next = pAdd; m_length++; } void addAtIndex (int index, int val) if (index > m_length) { return ; } MyNode* pNow = m_head; while (index--) { pNow = pNow->next; } MyNode* pAdd = new MyNode (val, pNow->next); pNow->next = pAdd; m_length++; } void deleteAtIndex (int index) if (index >= m_length) { return ; } MyNode* pNow = m_head; while (index--) { pNow = pNow->next; } MyNode* pDel = pNow->next; pNow->next = pDel->next; pDel->next = nullptr ; delete pDel; m_length--; } private : MyNode* m_head = nullptr ; int m_length = 0 ; };
# 3、206. 反转链表 容易想到,双指针一次遍历即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public : ListNode* reverseList (ListNode* head) { ListNode* pPre = nullptr ; ListNode* pNow = head; while (pNow) { ListNode* pNext = pNow->next; pNow->next = pPre; pPre = pNow; pNow = pNext; } return pPre; } };
递归版本比较抽象,忽略下面的注释,这样思考就行了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public : ListNode* reverseList (ListNode* pNow) { if (pNow == nullptr || pNow->next == nullptr ) { return pNow; } ListNode* tail = reverseList (pNow->next); pNow->next->next = pNow; pNow->next = nullptr ; return tail; } };
# 4、24. 两两交换链表中的节点 一开始想出来的方法需要用到 pre、cur、next 三个指针:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public : ListNode* swapPairs (ListNode* head) { if (head == nullptr || head->next == nullptr ) return head; ListNode* dummy = new ListNode (-1 , head); ListNode* pre = dummy; ListNode* cur = head; ListNode* next = cur->next; while (cur != nullptr && next != nullptr ) { pre->next = next; cur->next = next->next; next->next = cur; pre = cur; cur = cur->next; if (cur) { next = cur->next; } } return dummy->next; } }
但实际上两个指针就足够了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public : ListNode* swapPairs (ListNode* head) { if (!head || !head->next) return head; ListNode dummy = ListNode (555 ); ListNode* next = head->next; ListNode* last = &dummy; while (head && head->next) { next = head->next; head->next = next->next; next->next = head; last->next = next; last = head; head = head->next; } return dummy.next; } }
递归版本,同样地很抽象:swapPairs 函数,传入一个 head,处理 head 和 next 两个节点,然后把 next->next 作为新的 head 传入。
1 2 3 4 5 6 7 8 9 10 11 class Solution {public : ListNode* swapPairs (ListNode* head) { if (!head || !head->next) return head; ListNode* nextNode = head->next; head->next = swapPairs (nextNode->next); nextNode->next = head; return nextNode; } }
# 5、19. 删除链表的倒数第 N 个结点 #双指针 #快慢指针
可能是因为以前做过好几次了吧,看到题目死去的记忆就开始浮现出来了。
快慢指针均从链表头开始,快指针先走 n 步,然后快慢指针同时开始向后遍历,直到快指针遍历到链表尾部。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : ListNode* removeNthFromEnd (ListNode* head, int n) { ListNode* slow = head; ListNode* fast = head; while (n--) { fast = fast->next; } if (!fast) { ListNode* ret = head->next; delete head; return ret; } while (fast->next) { slow = slow->next; fast = fast->next; } ListNode* del = slow->next; slow->next = del->next; delete del; return head; } };
这里如果加上 dummy 结点会更简洁一点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public : ListNode* removeNthFromEnd (ListNode* head, int n) { ListNode* dummyHead = new ListNode (-1 , head); ListNode* pFast = dummyHead; ListNode* pSlow = dummyHead; while (n--) { pFast = pFast->next; } while (pFast->next) { pFast = pFast->next; pSlow = pSlow->next; } ListNode* pDel = pSlow->next; pSlow->next = pDel->next; delete pDel; return dummyHead->next; } };
# 6、面试题 02.07. 链表相交 #双指针 #快慢指针 #哈希
思路 1 :理由是:a + c + b = b + c + a ,而该公式的物理含义(可以画图看看),就是 A 指针走完 A 链表,又从 B 链表走到交叉点,同时 B 指针走完 B 链表,又从 A 链表走到交叉点。此时,指针相遇。m + n = n + m 成立,此时两指针均位于链表尾,下一次迭代时两个指针均为 nullptr ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) { if (headA == nullptr || headB == nullptr ) { return nullptr ; } ListNode *pA = headA, *pB = headB; while (pA != pB) { pA = (pA == nullptr ? headB : pA->next); pB = (pB == nullptr ? headA : pB->next); } return pA; } };
思路 2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public : ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) { ListNode* ret = nullptr ; ListNode* pDummyNodeA = new ListNode (-1 , headA); ListNode* pDummyNodeB = new ListNode (-1 , headB); int lengthA = 0 , lengthB = 0 ; for (ListNode* pNow = pDummyNodeA; pNow->next != nullptr ; pNow = pNow->next) { ++lengthA; } for (ListNode* pNow = pDummyNodeB; pNow->next != nullptr ; pNow = pNow->next) { ++lengthB; } int gap = 0 , distance = 0 ; ListNode* pNowLong = nullptr , *pNowShort = nullptr ; if (lengthA > lengthB) { gap = lengthA - lengthB; distance = lengthB; pNowLong = pDummyNodeA->next; pNowShort = pDummyNodeB->next; } else { gap = lengthB - lengthA; distance = lengthA; pNowLong = pDummyNodeB->next; pNowShort = pDummyNodeA->next; } while (gap--) { pNowLong = pNowLong->next; } for ( ; distance--; pNowLong = pNowLong->next, pNowShort = pNowShort->next) { if (pNowLong == pNowShort) { ret = pNowShort; break ; } } return ret; } };
思路 3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public : ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) { unordered_set<ListNode *> visited; ListNode *temp = headA; while (temp != nullptr ) { visited.insert (temp); temp = temp->next; } temp = headB; while (temp != nullptr ) { if (visited.count (temp)) { return temp; } temp = temp->next; } return nullptr ; } };
思路 4:
挺巧妙的。
# 7、142. 环形链表 II #哈希 #快慢指针
思路 1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : ListNode *detectCycle (ListNode *head) { unordered_set<ListNode*> visited; while (head) { if (visited.count (head)) { return head; } else { visited.insert (head); head = head->next; } } return nullptr ; } };
思路 2:
对于这个思路,我们需要确认两个问题:是否有环,以及(在有环的情况下)入环点在哪。
定义快慢两个指针,均从头开始向后遍历,慢指针每次走一步,快指针每次走两步。当快指针不为空时,持续迭代。
(且一定会在慢指针第一圈走不完的时候就会和快指针相遇。虽然这个信息没啥卵用。)
接下来是确定入环点:a + n(b+c) + b = a + (n+1)b + nc 。a + (n+1)b + nc = 2(a+b) ⟹ a = c + (n−1)(b+c)
这里,a 是我们要求的入环点的位置 / 距离,于是有:从相遇点到入环点的距离(c)加上 n−1 圈的环长( (n−1)(b+c) ),恰好等于从链表头部到入环点的距离。
于是,当我们找到相遇点时,我们再额外使用一个指针 ptr。起始,它指向链表头部;随后,它和 slow 每次向后移动一个位置。一旦他们相遇,那就是入环点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public : ListNode *detectCycle (ListNode *head) { if (!head) return nullptr ; ListNode* slow = head; ListNode* fast = head; while (fast) { if (!fast->next) return nullptr ; slow = slow->next; fast = fast->next->next; if (fast == slow) { ListNode* ptr = head; while (ptr != slow) { ptr = ptr->next; slow = slow->next; } return ptr; } } return nullptr ; } };
一些没用的讯息: